- AI, But Simple
- Posts
- Multimodal Machine Learning, Simply Explained

Hello from the AI, but simple team! If you enjoy our content, consider supporting us so we can keep doing what we do.
Our newsletter is no longer sustainable to run at no cost, so we’re relying on different measures to cover operational expenses. Thanks again for reading!
Multimodal Machine Learning, Simply Explained
AI, But Simple Issue #53
Multimodal machine learning is a recent trending field of ML algorithms that learn and identify relationships from multimodal datasets—datasets that contain multiple types of data, such as images, text, or audio.
In the real world, multimodal learning is one that takes advantage of multiple senses, such as giving a speech (audio) and pointing to a visual. This allows for a more complete view and deeper comprehension of the situation.
The same goes for ML models—the more data and modalities (types of data) we feed into the model, the more information it has to infer from to obtain an accurate prediction.
Consequently, researchers started to pose the question: If humans use five senses to experience the world around them, capturing loads of information, why not do the same with ML models?
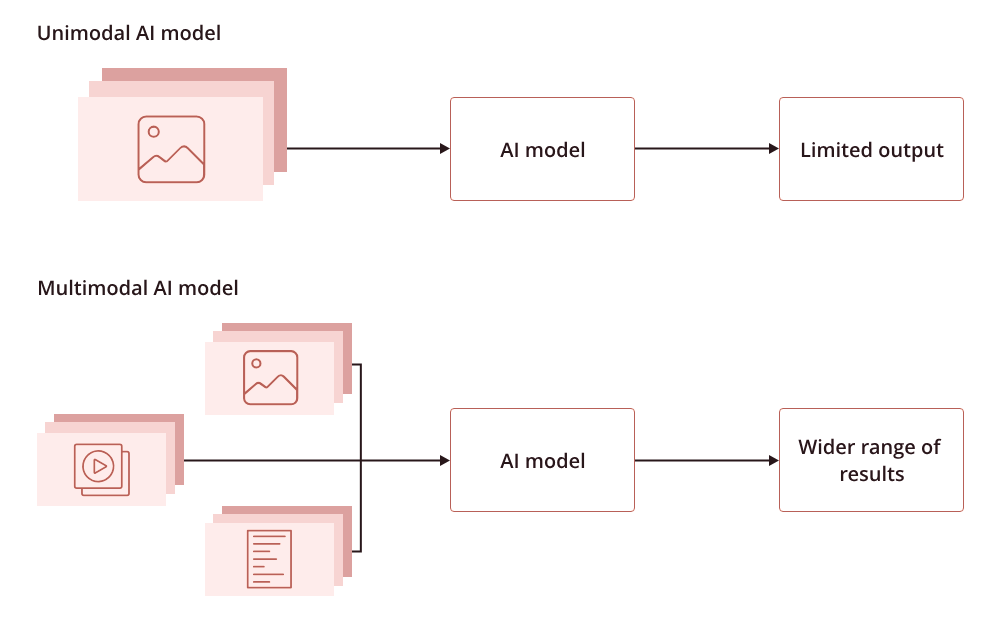
Currently, multimodal models can be found in many real-world applications, such as image captioning, emotion recognition, text-to-image generation, text-to-video generation, and much, much more. These applications combine unimodal data to form multimodal datasets.